SZZ materiály
9
Intervaly spolehlivosti, jejich význam, interpretace a konstrukce (definice, typy, interpretace spolehlivosti, resp. hladiny významnosti, výpočet [pro střední hodnotu, rozptyl, relativní četnost], vliv rozsahu výběru, využití v praxi)
Užitečné odkazy
- https://youtu.be/ENnlSlvQHO0?si=AdIjiFf65G5pjjNY (Intervaly spolehlivosti - v angličtině)
- https://youtu.be/5q2ac412hv4?si=ni0Gm9lBzqd6KsX0 (Intervaly spolehlivosti - v angličtině)
- https://youtu.be/IhqLdaJE27Q?si=hKEeYwf7LP7DUo1K (Intervaly spolehlivosti - v češtině)
Obecné poznatky
- interval spolehlivosti pro rozptyl nezkouší
- interval spolehlivosti pro průměr teoreticky stačí, ostatní je bonus
- umět říct, na čem závisí šířka intervalu spolehlivosti
Interval spolehlivosti
- anglicky confidence interval
- interval, pomocí kterého odhadujeme skutečnou hodnotu parametru populace na základě vzorku
- vyjadřuje nejistotu odhadu způsobenou tím, že nezkoumáme celou populaci
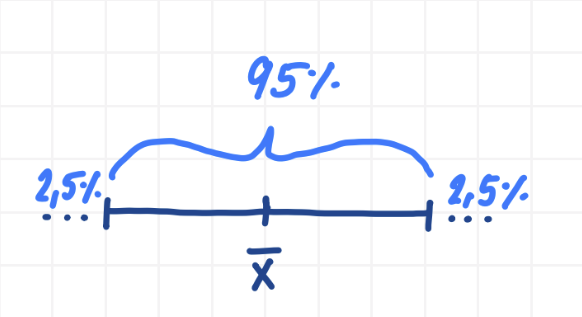
Uprostřed intervalu se nachází výběrový průměr $\bar{x}$, tedy bodový odhad skutečného populačního průměru $\mu$. Prostředních $95\%$ představuje interval spolehlivosti, tedy oblast nejpravděpodobnějších hodnot pro skutečný populační průměr. Zbývajících $5\%$ tvoří hladina významnosti $\alpha = 0.05$, která je u oboustranného intervalu rozdělena na dvě části: $2.5\%$ vlevo a $2.5\%$ vpravo.
Populace
- anglicky population
- také základní soubor
- množina všech objektů, která představuje celý zkoumaný celek
- skutečné vlastnosti populace většinou neznáme přesně
- pro odhad populace používáme vzorek a statistické odhady
- objekty populace mají individuální vlastnosti (pokud je to člověk, tak např. výška, váha, …)
- populace má statistické charakteristiky odvozené z vlastností všech jejích objektů (pokud jsou objekty lidé, tak např. průměrná výška, průměrná váha, …)
Matematicky: \(P=\{x_1,x_2,\dots,x_n\}\)
kde:
- $P$ je populace
- $x_i$ jsou jednotlivé objekty populace
- $n$ je velikost populace
Vzorek
- anglicky sample
- také výběrový soubor
- náhodně vybrané objekty z populace
- podmnožina objektů z populace použitá pro statistický odhad
- používá se pro odhad vlastností celé populace
- větší vzorek obvykle znamená přesnější odhad populace
- každý objekt vzorku je zároveň objektem populace
- malý vzorek -> široký interval spolehlivosti
- velký vzorek -> užší interval spolehlivosti
- definice malého/velkého vzorku je kontextuální
- 30 lidí:
- může být hodně v medicíně (léčba vzácného onemocnění)
- může být extrémně málo pro volební průzkum celé republiky
- 30 lidí:
Matematicky: \(S \subseteq P \qquad S=\{x_1,x_2,\dots,x_n\}\)
kde:
- $P$ je populace
- $S$ je vzorek
- $x_i$ jsou jednotlivé objekty vzorku (a zároveň tranzitivně objekty populace)
- $n$ je velikost vzorku
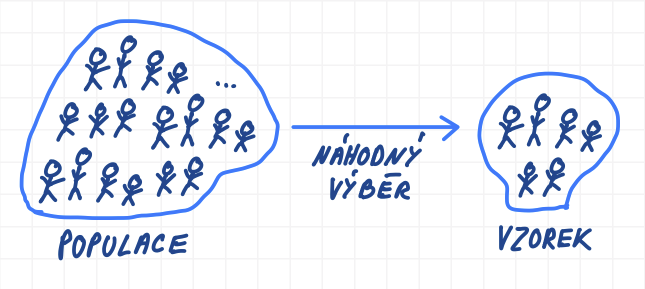
Příklad
- Populace: čeští muži ve věku 20 let
- Vzorek: 1000 náhodně vybraných českých mužů ve věku 20 let
- Zkoumaný parametr: průměrná výška českých můžu ve věku 20 let
Představme si, že chceme zjistit průměrnou výšku českých mužů ve věku 20 let. I když nemáme možnost oslovit a změřit výšku každého českého muže ve věku 20 let, tak můžeme z populace náhodně vybrat vzorek, např. 1000 mužů, u kterých výšku změříme. Prakticky to znamená, že náhodně oslovíme nějaký počet takových mužů. Ti muži, kteří se do našeho průzkumu zapojí, se nazývají respondenti. Na základě náhodného výběru vznikne námi naměřený vzorek (množina výšek českých mužů ve věku 20 let). Na základě vzorku provedeme statistický odhad parametru populace (parametrem je v tomto případě výška) a určíme interval spolehlivosti.
Interval spolehlivosti pro střední hodnotu
- anglicky confidence interval for the mean
- interval používaný pro odhad skutečné střední hodnoty populace na základě průměru vzorku
kde:
- $\bar{x}$
- průměr vzorku
- $s$
- směrodatná odchylka vzorku
- $n$
- velikost vzorku
- $\frac{s}{\sqrt{n}}$
- střední chyba průměru vzorku
- $t_{n-1}\left(1-\frac{\alpha}{2}\right)$
- kritická hodnota t-rozdělení
- kvantil t-rozdělení
- $\alpha$
- celková pravděpodobnost chyby
- $\frac{\alpha}{2}$
- pravděpodobnost chyby v jednom konci rozdělení
- $1-\frac{\alpha}{2}$
- kvantil použitý pro konstrukci oboustranného intervalu spolehlivosti
Kód
# vzorek
heights <- c(181, 176, 179, 182, 177, 180, 178, 175)
# n
n <- length(heights)
# x̄
x_bar <- mean(heights)
# s
s <- sd(heights)
# α
alpha <- 0.05
# t_(n-1)(1 - α/2)
t_value <- qt(1 - alpha / 2, df = n - 1)
# (s / sqrt(n))
standard_error <- s / sqrt(n)
# (s / sqrt(n)) * t_(n-1)(1 - α/2)
# chyba odhadu
margin_error <- standard_error * t_value
# dolní mez intervalu
lower <- x_bar - margin_error
# horní mez intervalu
upper <- x_bar + margin_error
# interval spolehlivosti
c(lower, upper)
nebo:
heights <- c(181, 176, 179, 182, 177, 180, 178, 175)
# x̄
mean(heights)
# x̄ ± (s / sqrt(n)) * t_(n-1)(1 - α/2)
t.test(heights)$conf.int
Interval spolehlivosti pro podíl
- anglicky confidence interval for a proportion
- vzorec
Příklad
- Populace: čeští muži ve věku 20 let
- Vzorek: 1000 náhodně vybraných českých mužů ve věku 20 let
- Zkoumaný parametr: podíl českých mužů ve věku 20 let vyšších než 180 cm
Interval spolehlivosti pro rozdíl
- anglicky confidence interval for the difference
- používá se pro odhad rozdílu mezi dvěma populacemi nebo skupinami
- odhadujeme:
- rozdíl středních hodnot (confidence interval for the difference of means)
- rozdíl podílů (confidence interval for the difference of proportions)
Příklad
- Populace 1: čeští muži ve věku 20 let
- Populace 2: čeští muži ve věku 30 let
- Vzorek 1: 1000 náhodně vybraných českých mužů ve věku 20 let
-
Vzorek 2: 1000 náhodně vybraných českých mužů ve věku 30 let
- Zkoumaný parametr: rozdíl průměrné výšky mezi českými muži ve věku 20 let a českými muži ve věku 30 let
Šířka intervalu spolehlivosti
- závisí na:
- na počtu pozorování (čím více pozorování, tím menší chyba, tím menší interval)
- na chybě
- na požadované spolehlivosti (čím větší, tím větší interval)
- na variabilitě (čím větší, tím větší interval)
Populační průměr
- skutečný průměr celé populace (základního souboru)
- většinou ho neznáme, protože ho většinou neumíme změřit
- př.: skutečná průměrná výška všech českých mužů ve věku 20 let
- neumíme změřit všechny české muže ve věku 20 let
- změřit ho můžeme pouze tehdy, máme-li přístup k celé populaci (např. poslední 3 nosorožci na světě v ohradě)
Značí se: \(μ\)
Výběrový průměr
- průměr spočítaný pouze ze vzorku (výběrového souboru)
- odhad populačního průměru
Značí se: \(\bar{x}\)
Hladina významnosti
- pravděpodobnost chyby I. druhu
- pravděpodobnost, že zamítneme nulovou hypotézu, i když je ve skutečnosti pravdivá
- alfa
Značí se: \(α\)