SZZ materiály
Relační databázové systémy a OLAP databáze
Užitečné odkazy
- https://github.com/ondrejsvorc/UJEP/tree/main/2.%20year/RDBS/zapocet
- https://github.com/ondrejsvorc/UJEP/tree/main/2.%20year/ODM/seminar-project
Ukázková úloha
Propojení a vizualizace dat ze dvou datových zdrojů
- Cizinci podle státního občanství, věku a pohlaví – rok 2019
- HDP na hlavu pro jednotlivé státy (lze samozřejmě použít i jiný relevantní zdroj)
Klíčové fáze řešení
- návrh struktury databáze (ER-diagram)
- vytvoření příslušných tabulek a relací
- vytvoření skriptu pro zpracování externích zdrojů a jejich vložení do databáze (včetně řešení nekonzistencí identifikátorů, chybějících dat apod.)
- spojení tabulek (JOIN)
- návrh a implementace dotazů
Doporučený výstup
- seskupení dat podle roků, státního občanství
- seskupení dat cizinců podle HDP na hlavu v zemích, kde mají státní občanství
- jednoduchá vizualizace výsledků
- návrh struktury datového skladu
Seznam dostupných materiálů a technologií
K dispozici bude Docker kontejner s oficiálním obrazem databázového systému PostgreSQL + Python s běžnými nástroji pro zpracování dat (NumPy, Pandas) + klient DBeaver.
Mé řešení ukázkové úlohy
Procesně bych nejdříve stáhl oba datové zdroje, podíval se na jejich strukturu a sjednotil identifikátory států ideálně přes ISO kódy; potom bych přes dbdiagram.io navrhl tabulky country, foreigners a gdp_per_capita s relacemi přes country_id. Dále bych napsal Python ETL skript pro načtení, očištění, mapování názvů států a vložení dat do databáze. Následně bych data propojil pomocí JOINů, připravil analytické dotazy pro seskupení podle roku, občanství, věku, pohlaví a HDP na hlavu a výsledky vizualizoval v Pythonu. Nakonec nakonec bych navrhl jednoduchý datový sklad ve hvězdicovém schématu s faktovou tabulkou cizinců a dimenzemi stát, čas, věk a pohlaví.
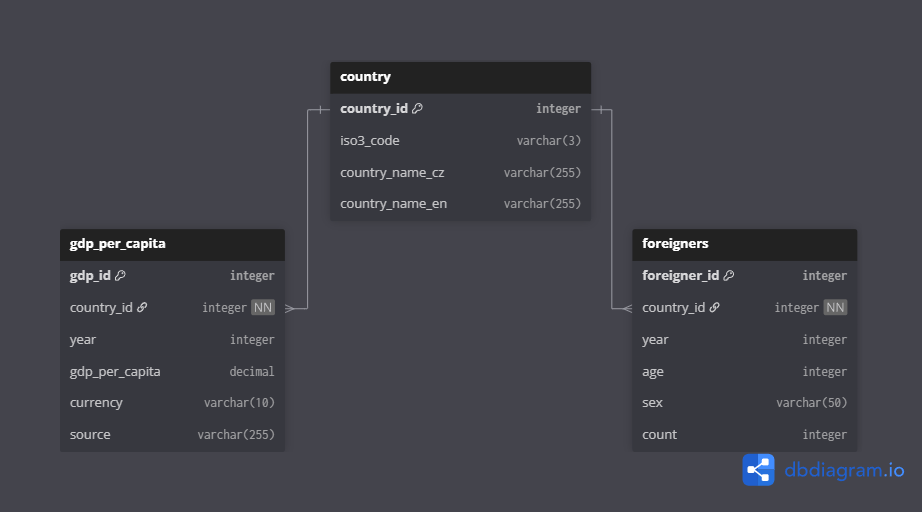
Table country {
country_id integer [pk, increment]
iso3_code varchar(3)
country_name_cz varchar(255)
country_name_en varchar(255)
}
Table foreigners {
foreigner_id integer [pk, increment]
country_id integer [not null]
year integer
age integer
sex varchar(50)
count integer
}
Table gdp_per_capita {
gdp_id integer [pk, increment]
country_id integer [not null]
year integer
gdp_per_capita decimal
currency varchar(10)
source varchar(255)
}
Ref: foreigners.country_id > country.country_id
Ref: gdp_per_capita.country_id > country.country_id
Vytvoření SQL tabulek
CREATE TABLE country (
country_id SERIAL PRIMARY KEY,
iso3_code CHAR(3) UNIQUE,
country_name_cz TEXT,
country_name_en TEXT
);
CREATE TABLE foreigners (
foreigner_id SERIAL PRIMARY KEY,
country_id INT REFERENCES country(country_id),
year INT NOT NULL,
age INT,
sex TEXT,
count INT NOT NULL
);
CREATE TABLE gdp_per_capita (
gdp_id SERIAL PRIMARY KEY,
country_id INT REFERENCES country(country_id),
year INT NOT NULL,
gdp_per_capita NUMERIC,
currency TEXT,
source TEXT,
UNIQUE (country_id, year)
);
Analytické SQL dotazy
-- Počet cizinců podle roku, státního občanství a HDP na hlavu
SELECT Foreigners.year, Country.country_name_cz, SUM(Foreigners.count) AS foreigners_count, GdpPerCapita.gdp_per_capita
FROM foreigners AS Foreigners
INNER JOIN country AS Country ON Foreigners.country_id = Country.country_id
LEFT JOIN gdp_per_capita AS GdpPerCapita ON Foreigners.country_id = GdpPerCapita.country_id AND Foreigners.year = GdpPerCapita.year
GROUP BY Foreigners.year, Country.country_name_cz, GdpPerCapita.gdp_per_capita
ORDER BY foreigners_count DESC;
-- Počet cizinců podle státního občanství
SELECT Country.country_name_cz, SUM(Foreigners.count) AS foreigners_count
FROM foreigners AS Foreigners
INNER JOIN country AS Country ON Foreigners.country_id = Country.country_id
WHERE Foreigners.year = 2019
GROUP BY Country.country_name_cz
ORDER BY foreigners_count DESC;
-- Cizinci podle pásem HDP na hlavu
SELECT
CASE
WHEN GdpPerCapita.gdp_per_capita < 10000 THEN 'nízké HDP'
WHEN GdpPerCapita.gdp_per_capita < 30000 THEN 'střední HDP'
ELSE 'vysoké HDP'
END AS gdp_group,
SUM(Foreigners.count) AS foreigners_count
FROM foreigners AS Foreigners
INNER JOIN gdp_per_capita AS GdpPerCapita ON Foreigners.country_id = GdpPerCapita.country_id AND Foreigners.year = GdpPerCapita.year
GROUP BY gdp_group
ORDER BY foreigners_count DESC;
Vizualizace v Pythonu
-- Věková struktura podle země
SELECT Country.country_name_cz, Foreigners.age, Foreigners.sex, SUM(Foreigners.count) AS foreigners_count
FROM foreigners AS Foreigners
INNER JOIN country AS Country ON Foreigners.country_id = Country.country_id
WHERE Foreigners.year = 2019
GROUP BY Country.country_name_cz, Foreigners.age, Foreigners.sex;
import os
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sqlalchemy import create_engine
# pip install pandas matplotlib seaborn sqlalchemy psycopg
DB_URL = os.getenv(
"DB_URL",
"postgresql+psycopg://postgres:postgres@localhost:5432/postgres"
)
engine = create_engine(DB_URL)
query = """
SELECT
f.year,
c.country_name_cz AS country,
f.age,
f.sex,
SUM(f.count) AS foreigners_count,
g.gdp_per_capita
FROM foreigners f
JOIN country c ON f.country_id = c.country_id
LEFT JOIN gdp_per_capita g
ON f.country_id = g.country_id
AND f.year = g.year
WHERE f.year = 2019
GROUP BY
f.year,
c.country_name_cz,
f.age,
f.sex,
g.gdp_per_capita
"""
df = pd.read_sql(query, engine)
sns.set_theme(style="whitegrid")
# 1. Top 10 občanství podle počtu cizinců
top10 = (
df.groupby("country", as_index=False)["foreigners_count"]
.sum()
.sort_values("foreigners_count", ascending=False)
.head(10)
)
plt.figure(figsize=(10, 5))
sns.barplot(data=top10, x="foreigners_count", y="country")
plt.title("Top 10 občanství podle počtu cizinců")
plt.xlabel("Počet cizinců")
plt.ylabel("Státní občanství")
plt.tight_layout()
plt.savefig("top10_obcanstvi.png")
plt.show()
# 2. Scatter plot: HDP na hlavu vs. počet cizinců
scatter = (
df.groupby(["country", "gdp_per_capita"], as_index=False)["foreigners_count"]
.sum()
.dropna()
)
plt.figure(figsize=(8, 5))
sns.scatterplot(
data=scatter,
x="gdp_per_capita",
y="foreigners_count",
size="foreigners_count",
legend=False
)
plt.title("HDP na hlavu vs. počet cizinců")
plt.xlabel("HDP na hlavu")
plt.ylabel("Počet cizinců")
plt.tight_layout()
plt.savefig("hdp_vs_cizinci.png")
plt.show()
# 3. Boxplot podle skupin HDP
df["gdp_group"] = pd.cut(
df["gdp_per_capita"],
bins=[0, 10000, 30000, float("inf")],
labels=["nízké HDP", "střední HDP", "vysoké HDP"]
)
gdp_groups = (
df.groupby(["country", "gdp_group"], as_index=False, observed=True)["foreigners_count"]
.sum()
.dropna()
)
plt.figure(figsize=(8, 5))
sns.boxplot(data=gdp_groups, x="gdp_group", y="foreigners_count")
plt.title("Rozložení počtu cizinců podle skupin HDP")
plt.xlabel("Skupina HDP")
plt.ylabel("Počet cizinců")
plt.tight_layout()
plt.savefig("boxplot_hdp_skupiny.png")
plt.show()
# 4. Heatmapa: věk × pohlaví pro vybrané občanství
selected_country = top10.iloc[0]["country"]
heatmap_data = (
df[df["country"] == selected_country]
.pivot_table(
index="age",
columns="sex",
values="foreigners_count",
aggfunc="sum",
fill_value=0
)
)
plt.figure(figsize=(7, 10))
sns.heatmap(heat)
Návrh datového skladu
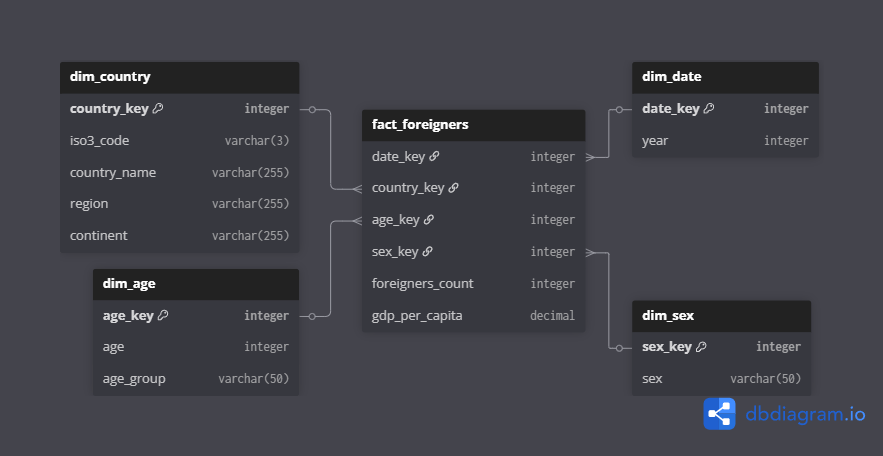
Table fact_foreigners {
date_key integer
country_key integer
age_key integer
sex_key integer
foreigners_count integer
gdp_per_capita decimal
}
Table dim_country {
country_key integer [pk]
iso3_code varchar(3)
country_name varchar(255)
region varchar(255)
continent varchar(255)
}
Table dim_date {
date_key integer [pk]
year integer
}
Table dim_age {
age_key integer [pk]
age integer
age_group varchar(50)
}
Table dim_sex {
sex_key integer [pk]
sex varchar(50)
}
Ref: fact_foreigners.country_key > dim_country.country_key
Ref: fact_foreigners.date_key > dim_date.date_key
Ref: fact_foreigners.age_key > dim_age.age_key
Ref: fact_foreigners.sex_key > dim_sex.sex_key